
QwQ-32B: A Medium-Sized Model with Big Potential
GPT o1 level performance on almost consumer hardware

Meet QwQ-32B, a model that’s been catching attention in the AI community without all the hype. This 32-billion-parameter model is designed for reasoning tasks and packs quite a punch.

Why Reinforcement Learning Matters
You’ve probably heard about reinforcement learning, if you’re into tech news. It’s like teaching an AI to learn by trial and error, getting feedback from its environment. Imagine it as learning chess by playing games and seeing whether your moves win or lose points—except for AI tasks.
What makes RL special is that it doesn’t rely solely on pre-training data. Instead, it allows models to adapt and improve in real-time, much like how humans learn from their mistakes. This approach has been a big step forward, especially when combined with high-quality feedback loops.
For QwQ-32B, RL isn’t just an extra feature; it’s central to its design. By integrating RL during training, the model learns to tackle complex tasks more effectively than traditional methods alone.
Specs: The Numbers That Matter
QwQ-32B has 32 billion parameters, putting it in the same league as larger models but with a smaller footprint. This makes it more accessible for those who don’t have massive cloud servers. It’s open-source and available on Hugging Face and ModelScope under the Apache 2.0 license.
One of its standout features is its ability to match bigger models like DeepSeek-R1 in performance. Despite having fewer parameters (and by extension less detailed knowledge of the world), QwQ-32B holds its own, showing that it’s not always about size but how you use what you have.
How It Measures Up: Benchmarks and Beyond
QwQ has been tested across various benchmarks for mathematical reasoning, coding proficiency, and general problem-solving. The results? Comparable to bigger models like DeepSeek-R1 (671B) and by extension other SOTA models.
This is a big deal because it shows that efficiency can meet performance head-on. For developers looking to balance resource usage with model effectiveness, QwQ-32B is a solid choice.
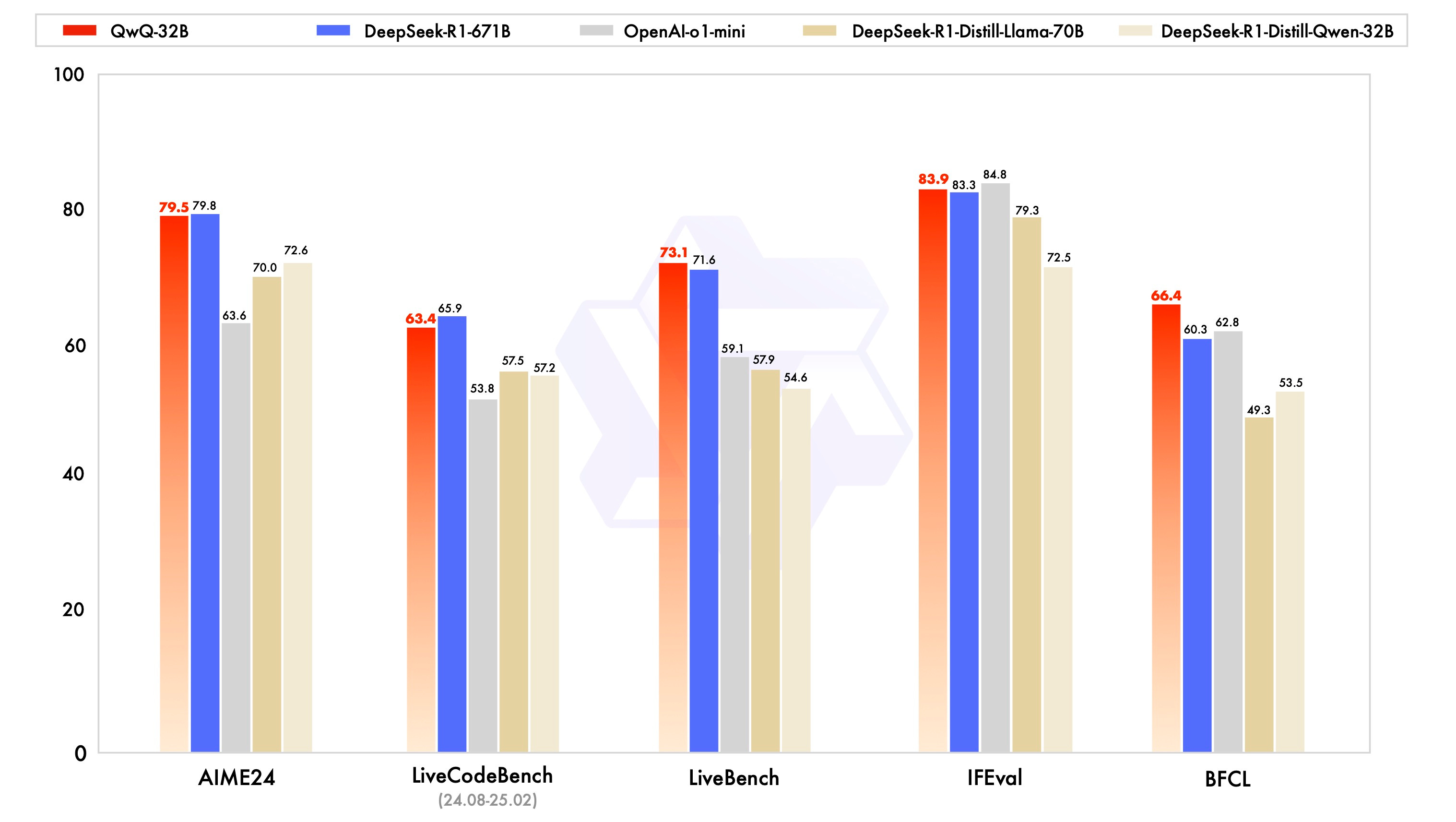
However, initial testing by the community showed, that for QwQ to come up with the same quality answers as larger models, it needs to spend more output tokens on reasoning. Meaning its “initial thinking” phase takes is less efficient, and it takes longer to come up with its final answer.
Getting Started: Accessibility for All
The best models are only as good as how easy they are to use. Fortunately, QwQ-32B comes with user-friendly access points:
Demo: Check it out without any setup at demo link.
Local Installation: Use Ollama to run it locally with ease via Ollama.
Hugging Face Repository: Find it under the Qwen models on Hugging Face: Hugging Face repo link.
Introduction Post: Learn more in this detailed intro: intro post link.
The Future Looks Bright
QwQ-32B isn’t just another model; it’s a great example of efficient design and smart training techniques. Its ability to perform well on par with larger models while being more resource-efficient opens up possibilities for a wider range of applications.
For those looking to experiment without sacrificing performance, QwQ-32B is an excellent choice. It’s like having a powerful tool in your arsenal that doesn’t require specialized hardware for the task at hand.